Asynchronous versus Synchronous Nodes
Earlier this year, I wrote an entry about how LabVIEW's data-flow execution semantics works. There's an additional aspect of parallelism in LabVIEW that I didn't talk about: synchronous versus asynchronous nodes. A LabVIEW diagram that has parallelism in it can still appear to run in parallel on a single processor machine. The 55ms ping-pong was an example of that. Here's another example: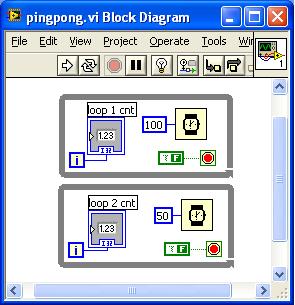
The top loop will run and update the indicator with the value of the loop counter while waiting for 100ms, and then repeat. The bottom loop will run and update the indicator with the value of the loop counter while waiting for 50ms, and then repeat.
The LabVIEW diagram used cooperative multithreading. LabVIEW itself didn't go to "sleep" when the top loop tried to wait for 100ms.
Instead, LabVIEW would execute the top wait for 100ms by setting a timer to go off in 100ms. Then, it would look for other parts of the diagram that could still run (like the bottom loop) and run it until that 100ms timer alarmed. When the timer went off, LabVIEW would take control back and finish executing the top diagram. The wait node was called "asynchronous" because it would let the execution system continue even though an operation (the wait) wasn't finished yet.
Well, operating systems have grown up and now we can spawn "threads". Rather than having the LabVIEW execution system use just one thread, we could allow it to use multiple threads. So when LabVIEW tried to execute a node that did block the execution system (we call those, "synchronous"), there might be another OS thread available to get work done.
You may see this when you call some C code that uses the "sleep()" call. The DLL doesn't return so the current thread is blocked but the CPU should be free to do other things. Since LabVIEW has other threads available to it, it will keep executing in the other threads.
So why continue to have asynchronous nodes at all? If you put 500 wait nodes on the diagram, we would in theory have to allocate 500 threads. Operating systems don't like that very much so we don't do that. Instead, we keep the old cooperative multitasking system but augment it by having each diagram use 4 threads. This gives LabVIEW the ability to work with external code that blocks and still have efficient execution for primtives LabVIEW knows about.
Why talk about all of this? Because sometimes we expose this to you and ask you to pick. The VISA read and VISA write nodes expose a property that let you decide whether they are synchronous or not. We even wrote an appnote on it. But, you can't read the appnote without understanding the stuff above, otherwise you'll think that asynchronous means that the node itself will return early. It won't. The setting only affects how LabVIEW internally chooses to execute the node. So why would you pick? In the words of one of our very experienced LabVIEW developers:
Frequently, VISA is used for serial I/O. If you know the instrument has data ready (e.g., you just asked for the number of bytes waiting to be read), a synchronous read will be much faster, since it won't use LabVIEW's execution scheduling mechanisms to poll the I/O.
There you have it.
posted by Joel @ 4:16 PM
3 comments
![]()
![]()



