This topic came as a result of a customer question at a NITS session. NITS is our travelling version of NIWeek. We take the best presentations on the road to a variety of cities to get our technical information out to an even wider audience. We even send our development engineers out to give the presentations because we feel like having direct customer contact is the best way for the people implementing the features to understand what people need. Someone asked what the performance impact was of using property nodes to set values on controls. I thought I'd share my version of the answer here.
The typical way of setting the value of a LabVIEW control or indicator is to pass data via a data-flow wire to the terminal. Since this is the typical case, we do the most to optimize the performance of this case. When you write to a terminal and the front panel is open, the data gets copied to a temporary holding spot called the transfer buffer. After some interval (around 60 Hz), the UI steals some time from the running program and updates the controls by copying the data from any changed transfer buffers to the control and then redraws the changed controls. So, to summarize
- If the front panel is in memory (which can happen for a number of reasons - including running a VI that has been edited or upgraded to a new version without being saved)
- Every time the terminal node or local variable executes, data gets copied once. The diagram immediately continues after the data copy.
- Around 60 Hz, the control updates if the data changed
A property node for a control or indicator has a property called "Value". It would seem to be the same, right? Not exactly, someone on one of the forums noted that its actually 600 times slower in their test. Why? Because property nodes use a different mechanism and are accomplishing a different thing. Property nodes are typically used to set other options on the control, such as its color or formatting. So when you use a property node, here's what happens
- The front panel will always be forced in memory if there is a property node to it on any diagram (thus slowing down other normal indicator updates as noted above)
- The execution of the property node forces the block diagram to pause while LabVIEW wakes up the front panel. (i.e. switches threads to the UI thread)
- The front panel then does whatever operation was asked (such as changing the value of the control)
- The front panel then forces a redraw of the affected part of the screen (typically if the data changed but sometimes always)
- Then LabVIEW switches back to the block diagram and continues
So, you get two thread swaps and a screen redraw every time you update the "value" of the control. 600x slowdown is not at all surprising when you know how things actually work
There are a couple of optimizations that you can do here
- Don't use the value property unless you have no other alternative
- If you are doing more than 1 property update or are doing some sort of looping, take the VI that is doing the updating and set its execution system to "UI Thread". That will move the thread swaps to the boundary of the VI rather than having them happen on each property node call
- Look into the "DeferPanelUpdates" property.
Technorati Tags: LabVIEW, Performance, Programming
Back when I was six, I had newfangled handheld computers games that adults couldn't figure out. Between the ages of 12 and 16, it seemed no adult could stop a VCR from flashing "12:00". In the blogging world, I feel like my creaky grandfather. Someone says "Web 2.0" and I say "what?"
Anyway, there are some new little widgets that you might find useful
In the top right, there's a list of articles I've
read recently that you might enjoy. They are updated semi-automagically as I surf so they should stay current. You might find the articles interesting. Hopefully it's more useful information that what I'm playing on my iPod.
There is now a way to get email whenever I post something for those of you who aren't much for my irregular schedule or don't use an
RSS reader.
For those of you who do use a reader, I'd greatly appreciate it if you change over to my
new feed. Feedburner gives me statistics on who's reading my blog. The more people I know are reading it, the more incentive I have to write more (is there anybody out there... out there... out there... echo... echo...)
Many of you write code on a desktop computer that is supposed to run on a desktop computer. It may be in LabVIEW, in C, C++, VB, Java, or some other language. That makes you a desktop programmer, right? Well, not so fast. The term "Embedded" is so nebulous that sometimes the definition is "anything that's not a desktop". Wikipedia has a
decent definition for embedded. It says
An embedded system is a computer-controlled system. The core of any embedded system is a microprocessor, programmed to perform a few tasks (often just one task). This is to be compared to other computer systems with general purpose hardware and externally loaded software.
The key to being an embedded system is not the hardware it runs on, it's all in the software. Embedded systems have a particular task and they perform that task and nothing else. A Dell PC might be capable of being a desktop computer, but if you put software on it that turns it into something that does a particular task and only that task, it has then become an embedded system.
NI makes products that get used in a lot of embeded systems. Our customers take our products and turn them into, say, a Formula One brake test system, or a centrifuge control system. The brake test system uses an industrial PC with a Pentium 4 processor, but the application on that PC is designed to performa a particular function. It has a display that shows what the system is doing, and the operator only interacts with that system. The operator would never stick a "Quake" CD into the drive and start playing a game.
But embedded systems programming is hard, right? Yes and no. It's all about scale. If your embedded application can run on a desktop PC, then embedded programming is rather easy. Get yourself some good tools (which could even be free), take advantage of all of the thousands of programmer-years that go into Windows or Linux, and you're set. There are different form-factors for PCs, such as rugged chassis like PXI, that allow use in much more harsh environments than you would ever put something you bought from CompUSA.
The trick of embedded programming comes when you can't use PC hardware anymore. That laptop of yours doesn't fit in the pocket very well and weights a ton. The key-fob for unlocking you car has only 4 specially marked buttons rather than 101. But it's all a matter of scale. The more you optimize your hardware to match your application, the more pain you go through. But it doesn't change the type of application you are creating. You're still an "embedded programmer".
Technorati Tags
Embedded Programming, Dell, gcc
The term "data-flow" encompasses a lot of different types of execution. You might hear about "synchronous dataflow", or "process networks". LabVIEW uses "structured dataflow". Each node on a LabVIEW diagram has a set of inputs and a set of outputs. LabVIEW schedules each node to execute when one item of data has arrived on all of its inputs. The execution of the node generates all of the outputs which then trigger the following nodes to run. There is no queueing on wires unless you explicitly put a queue primitive node on the diagram. Looping (using structures such as For-loops and while-loops) are explicit rather than being implicit like in some other languages.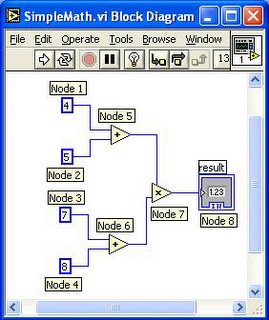
So, in this diagram, you can see that everything is a node. Even the constants are nodes. Node 1, 2, 3, and 4 have no inputs, just outputs. So, when the diagram runs, they can go first because they aren't waiting on anything. Node 5 waits until Nodes 1 and 2 have run. Node 6 waits on nodes 3 and 4 to run and then it runs. Node 7 waits until nodes 5 and 6 have run and then it runs. Finally, Node 8 runs. Easy to show.
So how do you implement something like this? First, it depends on the hardware you are running on. As you can see, there are a number of things that can run simultaneously. Nodes 1, 2, 3, and 4 can all run in parallel with each other since they have no dependencies. Nodes 5 and 6 can run in parallel since they don't have any dependencies. In a processing environment that supports parallelism, you could run a lot of the diagram in parallel. Node 7 is a synchronization point. It needs to wait for two different parallel operations (node 5 and node 6) to complete before it can continue.
How efficiently you can run this diagram will depend on three things
- How much parallel hardware is available. Can the hardware perform two adds in parallel?
- The overhead of scheduling each operation
The overhead of synchronizing at Node 7
Silicon logic is probably the ultimate parallel processing technology. The
FPGA makes this technology accessible to those without a semiconductor fab at their disposal and
LabVIEW FPGA makes it accessible so you don't need a degree in a complex language like VHDL to use it. If you run this diagram on an FPGA via LabVIEW FPGA, it will specify that the FPGA should make two blocks of hardware that perform adds in parallel and then feed the data into node 7 to do the multiply. The scheduling and synchronization overhead will depend upon how you draw this diagram. In the above diagram, LabVIEW FPGA wants to be safe. It will take each output wire and turn it into a register. So, the add at node 5 will occur and the data will go into a register and wait for the clock tick to come in order to pass the data on to node 7. This is how the data is synchronized. The scheduling overhead consists of a signal that travels from node 5 to the register to tell it "data is ready" and the signal that travels to node 7 that says "ok, now you can go". it takes up space but doesn't affect speed.Now, it turns out that this safety is a little paranoid. It turns out that the two parallel adds complete is a very short amount of time. In fact, the two adds can complete in parallel and then perform the multiply all in just one clock cycle. Since you know that, you can put this diagram into what is known as a 'single cycle timed loop'. This tells the FPGA module to remove the overhead of the register between node 5 and node 7. So, FPGAs have a lot of parallel hardware and can nearly eliminate the scheduling and synchronization overhead. What's the downside? Every single operation consumes a little bit of hardware and the FPGAs aren't terribly big. That 100 VI project isn't going to fit. Also, there are some primitives that don't work in the FPGA.So what about microprocessors? A microprocessor is mainly a sequential programming engine. You give it some sequential instructions and it performs them. Some processors (like modern desktop ones) can extract a bit of parallelism from the sequential instructions. A Pentium can run a couple add or multiply instructions in parallel. Now that multicore processors are
becoming more common, they can handle multiple sets of sequential instructions at once. How do you implement a structured dataflow engine in one of them? A basic dataflow scheduler has a big lookup table with a list of all of the nodes. It keeps track of which node feeds data to which and what data each node is waiting for. After each operation, the table gets updated with which nodes are waiting on which data and then which node is ready to run. In a paper I once read (that I can't find any more) this was called "fine grained dataflow". Easy, right? Well, yes but terribly inefficient. An "add" instruction in a microprocessor might take 1 clock cycle but the maintenance of that table may take 50 clock cycles or more. Having a scheduling overhead of 50:1 does not make for an efficient machine. Researchers have some
techniques for reducing this overhead and some dataflow processors have also reduced the overhead in hardware. In the paper I read published many years ago, they stated that none of these techniques had really been commercially successful.
Now, one thing to notice is that computations are not particularly sensitive to the outside world. For example, if you can't execute node 5 and node 6 in parallel, it really doesn't matter the order in which you execute the instructions. You get the same answer and the operation takes the same amount of time if you do the node 5 add and then the node 6 add or vice versa. Thus, LabVIEW forms "clumps" of instructions which are all basically sequential and then only does scheduling when a clump of instructions is done (using something more efficient than the table lookup by the way). So, the LabVIEW compiler might emit something like
Put "4" in register 1
Put "5" in register 2
Put "7" in register 3
Put "8" in register 4
Add registers 1 and 2 and store it back in register 2
Add registers 3 and 4 and store it back in register 4
Multiply registers 2 and 4 and store it back in register 2
Store register 2 in memory somewhere
Look for the next clump to run
This is all sequential code. While it might have been possible for the "add" in #5 and the "add" in #6 to run in parallel on different processors, the overhead of now trying to send the instruction to a separate processor and keep track of the synchronization and scheduling is so huge that you wouldn't have gotten the benefit of running them in parallel.
Now, it so happens that this example is so small, that the folks at Intel and IBM do give us some parallelism. A Pentium has multiple instruction units. When executing this sequential set of instructions, it sees that the first sets of instructions use different registers. Thus, the operations to put numbers into registers will likely occur in parallel. It might only take 1 clock cycle to execute the first 4 instructions because they don't interfere with each other. Likewise, instructions 5 and 6 operate on different sets of registers and there are multiple adders inside a pentium. Thus, those two instructions will probably be executed in parallel in the next clock cycle. Instruction number 7 is where things get interesting. It can't execute until both 5 and 6 have completed. Thus, it can't execute in parallel with instructions 5 and 6. (In fact, on some older CPUs, there might be a multiple clock delay while it waited for instructions 5 and 6 to complete). Similarly, instruction 8 can't execute until instruction 7 is complete.
So, even on a single CPU machine, you can get some small amount of parallelism. As always, thank your Intel engineer for this.
Ok, so this article is getting long so I'll stop there. If you're a LabVIEW programmer, you hopefully understand a little better how things work under the hood. If you're a student of computer architecture or parallel programming (as I once was), always pay attention to the overhead of distributing your workload because it may swamp any savings you hope to gain.




