Asynchronous versus Synchronous Nodes
Earlier this year, I wrote an entry about how LabVIEW's data-flow execution semantics works. There's an additional aspect of parallelism in LabVIEW that I didn't talk about: synchronous versus asynchronous nodes. A LabVIEW diagram that has parallelism in it can still appear to run in parallel on a single processor machine. The 55ms ping-pong was an example of that. Here's another example: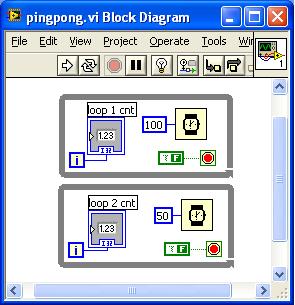
The top loop will run and update the indicator with the value of the loop counter while waiting for 100ms, and then repeat. The bottom loop will run and update the indicator with the value of the loop counter while waiting for 50ms, and then repeat.
The LabVIEW diagram used cooperative multithreading. LabVIEW itself didn't go to "sleep" when the top loop tried to wait for 100ms.
Instead, LabVIEW would execute the top wait for 100ms by setting a timer to go off in 100ms. Then, it would look for other parts of the diagram that could still run (like the bottom loop) and run it until that 100ms timer alarmed. When the timer went off, LabVIEW would take control back and finish executing the top diagram. The wait node was called "asynchronous" because it would let the execution system continue even though an operation (the wait) wasn't finished yet.
Well, operating systems have grown up and now we can spawn "threads". Rather than having the LabVIEW execution system use just one thread, we could allow it to use multiple threads. So when LabVIEW tried to execute a node that did block the execution system (we call those, "synchronous"), there might be another OS thread available to get work done.
You may see this when you call some C code that uses the "sleep()" call. The DLL doesn't return so the current thread is blocked but the CPU should be free to do other things. Since LabVIEW has other threads available to it, it will keep executing in the other threads.
So why continue to have asynchronous nodes at all? If you put 500 wait nodes on the diagram, we would in theory have to allocate 500 threads. Operating systems don't like that very much so we don't do that. Instead, we keep the old cooperative multitasking system but augment it by having each diagram use 4 threads. This gives LabVIEW the ability to work with external code that blocks and still have efficient execution for primtives LabVIEW knows about.
Why talk about all of this? Because sometimes we expose this to you and ask you to pick. The VISA read and VISA write nodes expose a property that let you decide whether they are synchronous or not. We even wrote an appnote on it. But, you can't read the appnote without understanding the stuff above, otherwise you'll think that asynchronous means that the node itself will return early. It won't. The setting only affects how LabVIEW internally chooses to execute the node. So why would you pick? In the words of one of our very experienced LabVIEW developers:
Frequently, VISA is used for serial I/O. If you know the instrument has data ready (e.g., you just asked for the number of bytes waiting to be read), a synchronous read will be much faster, since it won't use LabVIEW's execution scheduling mechanisms to poll the I/O.
There you have it.
posted by Joel @ 4:16 PM
![]()
![]()




3 Comments:
Joel, I'll take up this issue since I have been wiring heavily asynchronous diagrams for a long time. It is one of the primary advantages of LV over textural languages that dataflow is inherently mulitprocessing/multiprocessor aware.
But in using VISA it seems that Asynchronous nodes are inherently bad. This is very counter intuitive and I would like to hear your comments on this. It seems that a synchronous VISA node blocks that tread until it returns allowing the other threads to proceed. If it is asynchronous then internally VISA will POLL the transaction sucking CPU cycles from those other threads and reducing overall performance.
So, it seems that the upshot is for best asynchronous performance for VISA I/O the answer is to use SYNCHRONOUS VISA calls but allocate more threads and you expect for simultaneous VISA calls. I wrote a simple test VI where I could see that CPU resource usage went way down for using Synchronous calls rather than aysnchronous.
There is a threadconfig VI that allows you to change the number of threads allocated to each execution system. On a modern OS and quad processor machine one can allocate many more processes than the standard 4 (or actually 2/cpu) and using SYCHRONOUS VISA I/O and find a great reduction in CPU usage. A small example VI that I created for testing is at:
http://sthmac.magnet.fsu.edu/downloads/labview/Sych%20test%20HP34401.vi
Without getting into too many details, the asynchronous I/O only hogs the CPU if no other VI wants to run. I also thought that NI-VISA did some things to reduce CPU usage in your particular case, but maybe that was only on Windows, or only in the recent drivers.
I will say that we occasionally revisit the synchronous vs. ansynchronous default value from time to time.
One use case that concerns me is an application that opens up several serial ports and uses parallel, independent loops to read from the ports and process the data. There's no prior knowledge about when any of the various ports will get data, so that's why the loops are independent and parallel.
With synchronous I/O, this architecture works only up to the number of threads available (4), and fails when you add the fifth serial port. Asynchronous I/O would not have this limitation.
So, we opted for more compatibility over performance. We also took into consideration that with most message-based instrumentation, the cost of asynchronous I/O was tiny compared to the I/O itself. I'd be interested in your opinions.
Two things. One is the comment "the asynchronous I/O only hogs the CPU if no other VI wants to run." This is a very LV centric view!! (a LabVIEW VIEW to make very awkward term. I have other processes than LV running. Since it makes LV hog the CPU then to me it is wasted cycles. It may be that it shares CPU within labview but this is not taking the wider view of my environment. NI is not all things to all people, yet. :-)
As I understand it, the system is supposed to allocated 2 threads per hardware CPU. I know this is broken since my quad CPU system only has 4 threads (though it does show 4 CPUs). Now there are 4 threads at each of the 4 priorities for each of the 5 execution engines.
As I said, you can tweak this with vi.lib/Utility/Sysinfo.llb/ThreadConfig.vi. And if you plan on servicing N serial ports, I would suggest that you crank up the number of threads in the instr I/O execution engine to N+1 (always a little overhead).
My impression is that these are *fairly* lightweight threads and so there is not a lot of penalty for more, but I could be wrong on that. It seems that 2/cpu is not a lot any more.
I got into this with my highly asynchronous programs hogging a LOT of CPU and bogging the system down. That is when I generated that test VI and could measure a significant difference.
If you want a couple of big suggestions, then instead of setting the number of threads a system load time, spawn threads dynamically when an synchronous VISA operation occurs. It could be when the VISA open happens and stays with the VISA referernce or something like that.
The other would be to use a true notification system where the thread is truly sleeping until an interupt wakes it. This is a much cleaner interface and is much more in tune with what the user thinks an asynchronous node actually does. VISA notifiers are supposed to be like that (they aren't available on my platform of choice so I am not sure).
So, in summary, increase the number of threads and implement a true callback notifier structure for VISA. Simple, NO? :-)
Some of this should be written up in a white paper since there are folks doing 20 or 30 serial ports at a time!
Post a Comment
<< Home