Poll: Show Buffers?
LabVIEW has programming semantics of "by value". Data on a wire represents the "value" of that thing. You don't have "pointers" to data. You don't typically have "references", except when you are referring to certain objects like files or controls. Being a by-value language rather than a by-reference language makes programming in it less error prone and easier for folks to understand. However, for programmers experienced with languages that make extensive use of by-reference semantics (C & C++ come to mind), it requires a mental shift that some of them aren't happy with.But I'm not going to start that debate. Instead, I'll talk about the implication of by-value semantics. Let's take the basic case of adding two arrays.
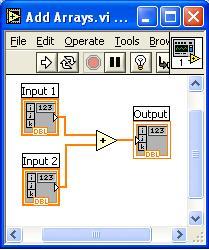
The semantics are easy, input 1 and input 2 are arrays. They get added together and placed into the output indicator. Now, a C programmer would look at this and say "aha! After an item in Input 2 is looked at, it isn't needed any more. I can save memory by taking the result of the addition and storing it back in the memory that was used for Input 2". That is a nice optimization. Unfortunately for the C developer, they would have to write their algorithm differently in order to do that optimization. They would have to store data back into the array by effectively using references.
In LabVIEW, there's no way to get a reference back to Input 2 and store the data back there. We really don't want you to do that anyway. Instead, we'd rather have LabVIEW figure it out and do it for you. And that's exactly what we do using something we call "the inplaceness algorithm". This algorithm figures out what memory locations can be reused to make the application take less memory and run more efficiently. Is this algorithm perfect? No. Does it work? Yes, quite well in fact.
We added a feature to LabVIEW in 7.0 via DevZone and as a true menu item in 7.1 to let you peek under the hood of LabVIEW and watch the inplaceness algorithm work. If you select Tools-->Advanced-->Show Buffer Allocations... you can see this tool in operation
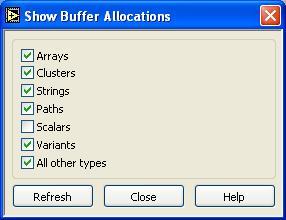
It shows you all of the places that LabVIEW decided that it couldn't reuse memory and had to create another buffer to hold the output data. I will say that this is an advanced tool. It doesn't interpret the location of the buffers, it just shows you where they are. It is not possible to get rid of all buffers, don't try. :-) You can find out a little more about how to use it by clicking the help button or looking at this help link. The LabVIEW Memory Management Application Note also gives you insight into what is going on.
So here's a question for the audience. Have you used this tool? Is it helpful? What else would you want to know? (no promises here folks)
posted by Joel @ 3:07 PM
![]()
![]()




6 Comments:
Yes, I have used it and I would use it even more often if I didn't have such a "quick and dirty" attitude. I think it gives important insight for performance improvement when manipulating large datasets. For making distributed software I think it is an important asset.
Use it once in a while if I really feel that there is a possible bottleneck.
Yep, use it regularly with RT applications.
I sometimes use it in regular LabVIEW when working with large strings, arrays and clusters.
I'm nearly a year late, but I thought I'd comment on a consequence of the pass-by-value behaviour: excessive buffer copying. Often I can't find a way to convice LV to not copy buffers, despite the fact that it's completely unnecessary. Could we please have the ability to define VI inputs as immutable? If the compiler knew that a certain buffer or cluster is positively not going to be modified during the execution of a certain VI, it could optimize memory allocation accordingly. That would be helpful in many instances.
Good suggestion. I've passed it along to the design team
By the way, I will note that LabVIEW isn't going to decide to copy a buffer just for the heck of it. Any buffer that isn't being modified will be internally marked as immutable and LabVIEW passes the data by pointer internally. What is most likely happening in your case is that even though you think the data isn't being modified, there really is a case that it could be and therefore LabVIEW decides it must make a copy.
For example, if you flow an array through a SubVI but the output terminal is inside a case statement, it will still make a buffer so it can handle the code path for the alternate case. The data doesn't appear to be modified. That's one reason why you always have output indicator terminals outside of loops and case statements.
Post a Comment
<< Home